Amazon Timestreamでデータ補間
これはInfocom Advent Calendar 2021 5日目の記事です.
経緯
自宅IoTのクラウド費用を月500円以下で構築するのを目的に,Amazon Timestreamを調べています. Timestreamには,欠損したデータなどをクエリ時に補間する関数が用意されているので,試してみました.
Timestreamとは
AWSのマネージド時系列データベースで,大量のデータをリアルタイムに高コスト効率で扱えます. たとえばIoTやコンピューティングメトリクス(CPU使用率など)のためのデータストアといったユースケースで利用します. 時系列に特化したSQL拡張があり,この記事ではそれを使ってみます.
ちなみに,日本リージョンではまだ使えません.
時系列関数
時系列関数には以下のようなものが用意されています.
- 補間(Interpolation)
- 微分(Derivatives)
- 積分(Integrals)
- 相関(Correlation)
- フィルタとリデュース(Filter and Reduce)
この記事では,上記にある補間の関数と,上記にはないですが日時系の関数であるbin()を使ってみます.
cf. Interpolation functions - Amazon Timestream
cf. Date / Time Functions - Amazon Timestream
サンプルデータ
以下のような温度データをサンプルデータとして書き込みます.
| time | place | temperature |
|---|---|---|
| 305秒前 | room1 | 21.5℃ |
| 199秒前 | room1 | 23.2℃ |
| 150秒前 | room1 | 22.8℃ |
| 133秒前 | room1 | 22.6℃ |
| 61秒前 | room1 | 23.5℃ |
| 33秒前 | room1 | 23.8℃ |
| 15秒前 | room1 | 24.5℃ |
| 5秒前 | room1 | 24.3℃ |
Amazon Timestreamの操作
以下のことをやってみます. なお,リージョンはus-west-2を使います.
- データベースの作成
- テーブルの作成
- サンプルデータの書き込み
- 時系列関数を使うSQLクエリの発行
データベースの作成
homeiotという名前のデータベースを作ります.
$ aws timestream-write create-database --database-name homeiot --region us-west-2テーブルの作成
homeiotデータベースにmeasuredという名前のテーブルを作ります. メモリストアの保持期間は24時間,マグネティックストアの保持期間は1825日(5年)としました.
$ aws timestream-write create-table \
--database-name homeiot \
--table-name measured \
--retention-properties '{"MemoryStoreRetentionPeriodInHours": 24, "MagneticStoreRetentionPeriodInDays": 1825}' \
--region us-west-2サンプルデータの書き込み
ここで宣言するcurrent変数は,このあとクエリを発行する際も使う基準時間です.
--common-attributesは使わなくてもよいですが,使うことで書き込み時のデータサイズを抑えられ,コスト効率が高くなります.
cf. Amazon Timestreamの料金計算方法 | ottijp blog
$ current=$(date +%s)
$ aws timestream-write write-records \
--database-name homeiot \
--table-name measured \
--common-attributes '{"Dimensions":[{"Name":"place", "Value":"room1"}], "MeasureName":"temperature", "MeasureValueType":"DOUBLE"}' \
--records "[{\"Time\":\"$(($current - 305))\", \"TimeUnit\":\"SECONDS\", \"MeasureValue\":\"21.5\"}, \
{\"Time\":\"$(($current - 199))\", \"TimeUnit\":\"SECONDS\", \"MeasureValue\":\"23.2\"}, \
{\"Time\":\"$(($current - 150))\", \"TimeUnit\":\"SECONDS\", \"MeasureValue\":\"22.8\"}, \
{\"Time\":\"$(($current - 133))\", \"TimeUnit\":\"SECONDS\", \"MeasureValue\":\"22.6\"}, \
{\"Time\":\"$(($current - 61))\", \"TimeUnit\":\"SECONDS\", \"MeasureValue\":\"23.5\"}, \
{\"Time\":\"$(($current - 33))\", \"TimeUnit\":\"SECONDS\", \"MeasureValue\":\"23.8\"}, \
{\"Time\":\"$(($current - 15))\", \"TimeUnit\":\"SECONDS\", \"MeasureValue\":\"24.5\"}, \
{\"Time\":\"$(($current - 5))\", \"TimeUnit\":\"SECONDS\", \"MeasureValue\":\"24.3\"}]" \
--region us-west-2時系列関数を使うSQLクエリの発行
それぞれの結果値をグラフにしたものは後述します.
書き込まれたサンプルデータを取得するクエリを発行してみます.
$ aws timestream-query query \
--query-string "SELECT time, measure_value::double \
FROM homeiot.measured \
WHERE place = 'room1' AND measure_name = 'temperature' AND time > from_iso8601_timestamp('$(date -u -r $(($current - 400)) +%FT%TZ)') \
ORDER BY time" \
--region us-west-2結果は以下のようになりました.
$ (上記コマンド) | jq ".ColumnInfo, .Rows"
[
{
"Name": "time",
"Type": {
"ScalarType": "TIMESTAMP"
}
},
{
"Name": "measure_value::double",
"Type": {
"ScalarType": "DOUBLE"
}
}
]
[
{
"Data": [
{
"ScalarValue": "2021-12-26 09:03:07.000000000"
},
{
"ScalarValue": "21.5"
}
]
},
{
"Data": [
{
"ScalarValue": "2021-12-26 09:04:53.000000000"
},
{
"ScalarValue": "23.2"
}
]
},
{
"Data": [
{
"ScalarValue": "2021-12-26 09:05:42.000000000"
},
{
"ScalarValue": "22.8"
}
]
},
{
"Data": [
{
"ScalarValue": "2021-12-26 09:05:59.000000000"
},
{
"ScalarValue": "22.6"
}
]
},
{
"Data": [
{
"ScalarValue": "2021-12-26 09:07:11.000000000"
},
{
"ScalarValue": "23.5"
}
]
},
{
"Data": [
{
"ScalarValue": "2021-12-26 09:07:39.000000000"
},
{
"ScalarValue": "23.8"
}
]
},
{
"Data": [
{
"ScalarValue": "2021-12-26 09:07:57.000000000"
},
{
"ScalarValue": "24.5"
}
]
},
{
"Data": [
{
"ScalarValue": "2021-12-26 09:08:07.000000000"
},
{
"ScalarValue": "24.3"
}
]
}
]次に,60秒単位のbinを作る行うクエリを発行してみます. binの値はbinの中のサンプルデータの平均値です.
$ aws timestream-query query \
--query-string "SELECT BIN(time, 60s) AS binned_timestamp, ROUND(AVG(measure_value::double), 1) AS avg_temperature \
FROM homeiot.measured \
WHERE place = 'room1' AND measure_name = 'temperature' AND time > from_iso8601_timestamp('$(date -u -r $(($current - 400)) +%FT%TZ)') \
GROUP BY place, BIN(time, 60s) \
ORDER BY binned_timestamp" \
--region us-west-2結果は以下のようになりました.
$ (上記コマンド) | jq ".ColumnInfo, .Rows"
[
{
"Name": "binned_timestamp",
"Type": {
"ScalarType": "TIMESTAMP"
}
},
{
"Name": "avg_temperature",
"Type": {
"ScalarType": "DOUBLE"
}
}
]
[
{
"Data": [
{
"ScalarValue": "2021-12-26 09:03:00.000000000"
},
{
"ScalarValue": "21.5"
}
]
},
{
"Data": [
{
"ScalarValue": "2021-12-26 09:04:00.000000000"
},
{
"ScalarValue": "23.2"
}
]
},
{
"Data": [
{
"ScalarValue": "2021-12-26 09:05:00.000000000"
},
{
"ScalarValue": "22.7"
}
]
},
{
"Data": [
{
"ScalarValue": "2021-12-26 09:07:00.000000000"
},
{
"ScalarValue": "23.9"
}
]
},
{
"Data": [
{
"ScalarValue": "2021-12-26 09:08:00.000000000"
},
{
"ScalarValue": "24.3"
}
]
}
]60秒単位のbinが作られ,binに含まれるサンプルデータの平均値がセットされました. ただし,サンプルデータが存在しない9:06台にはbinのデータは存在しません.
そこで,このbinのデータをベースに,INTERPOLATE_LINEAR関数で9:06台が補間されるようにクエリを発行してみます.
$ aws timestream-query query \
--query-string "WITH binned_timeseries AS (SELECT BIN(time, 60s) AS binned_timestamp, ROUND(AVG(measure_value::double), 1) AS avg_temperature \
FROM homeiot.measured \
WHERE place = 'room1' AND measure_name = 'temperature' AND time > from_iso8601_timestamp('$(date -u -r $(($current - 400)) +%FT%TZ)') \
GROUP BY place, BIN(time, 60s) \
) \
SELECT INTERPOLATE_LINEAR( \
CREATE_TIME_SERIES(binned_timestamp, avg_temperature), \
SEQUENCE(min(binned_timestamp), max(binned_timestamp), 60s)) AS interpolated_temperature \
FROM binned_timeseries" \
--region us-west-2結果は以下のようになりました.
$ (上記コマンド) | jq ".ColumnInfo, .Rows"
[
{
"Name": "interpolated_temperature",
"Type": {
"TimeSeriesMeasureValueColumnInfo": {
"Type": {
"ScalarType": "DOUBLE"
}
}
}
}
]
[
{
"Data": [
{
"TimeSeriesValue": [
{
"Time": "2021-12-26 09:03:00.000000000",
"Value": {
"ScalarValue": "21.5"
}
},
{
"Time": "2021-12-26 09:04:00.000000000",
"Value": {
"ScalarValue": "23.2"
}
},
{
"Time": "2021-12-26 09:05:00.000000000",
"Value": {
"ScalarValue": "22.7"
}
},
{
"Time": "2021-12-26 09:06:00.000000000",
"Value": {
"ScalarValue": "23.299999999999997"
}
},
{
"Time": "2021-12-26 09:07:00.000000000",
"Value": {
"ScalarValue": "23.9"
}
},
{
"Time": "2021-12-26 09:08:00.000000000",
"Value": {
"ScalarValue": "24.3"
}
}
]
}
]
}
]INTERPOLATE_LINEAR関数が返すのはtimeseries型なので,そのままではbinのみの場合とはフォーマットが違いますが, 9:06台の値が,9:05台と9:07台の値から線形補間されていることがわかります.
視覚化
コマンドと数値だけだとわかりづらいので,散布図にプロットしました.
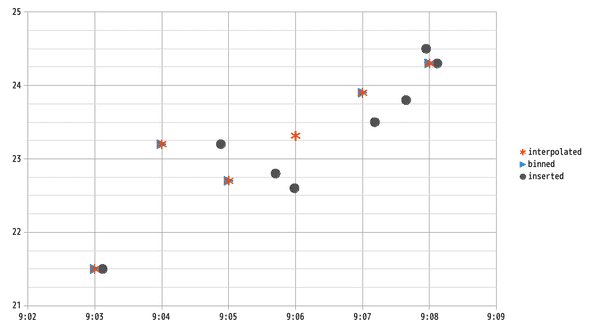
黒丸のサンプルデータが青三角の60秒単位のbinに平均化され,データの無い9:06台も補間関数を使うことで補間されたことがわかります(オレンジのアスタリスク).
実際のユースケースでは,欠損したデータをアプリケーションのロジックで補間することがあると思いますが, Timestreamの補間関数を使うことで,クエリの組み立てだけで補間が実現できるので便利です.